



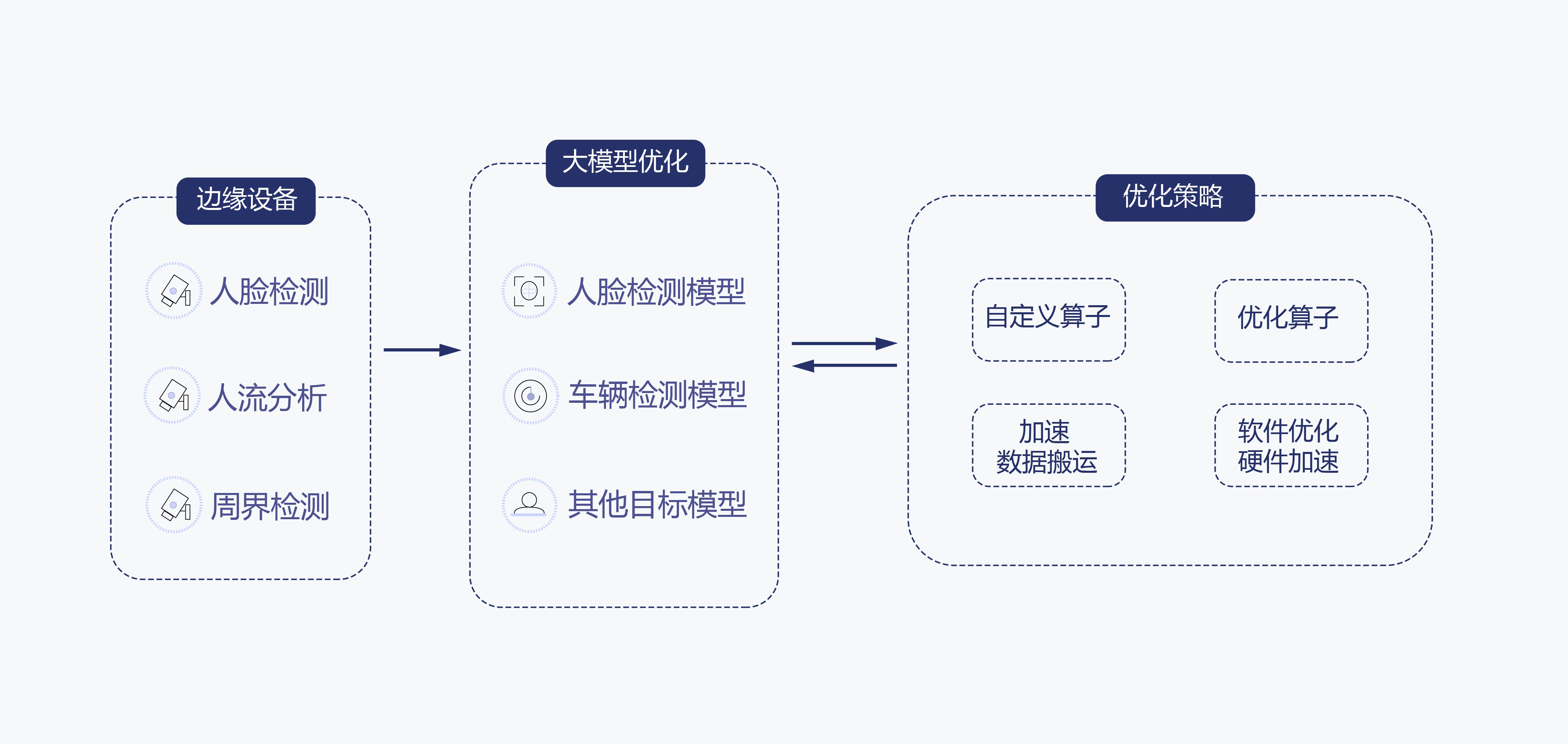
大模型算力优化的优势
基于算法优化、并行计算等技术,提高计算任务的执行速度,通过有效利用现代硬件(如GPDTPU等)进行计算加速,减少计算或说句中心的运行成本。
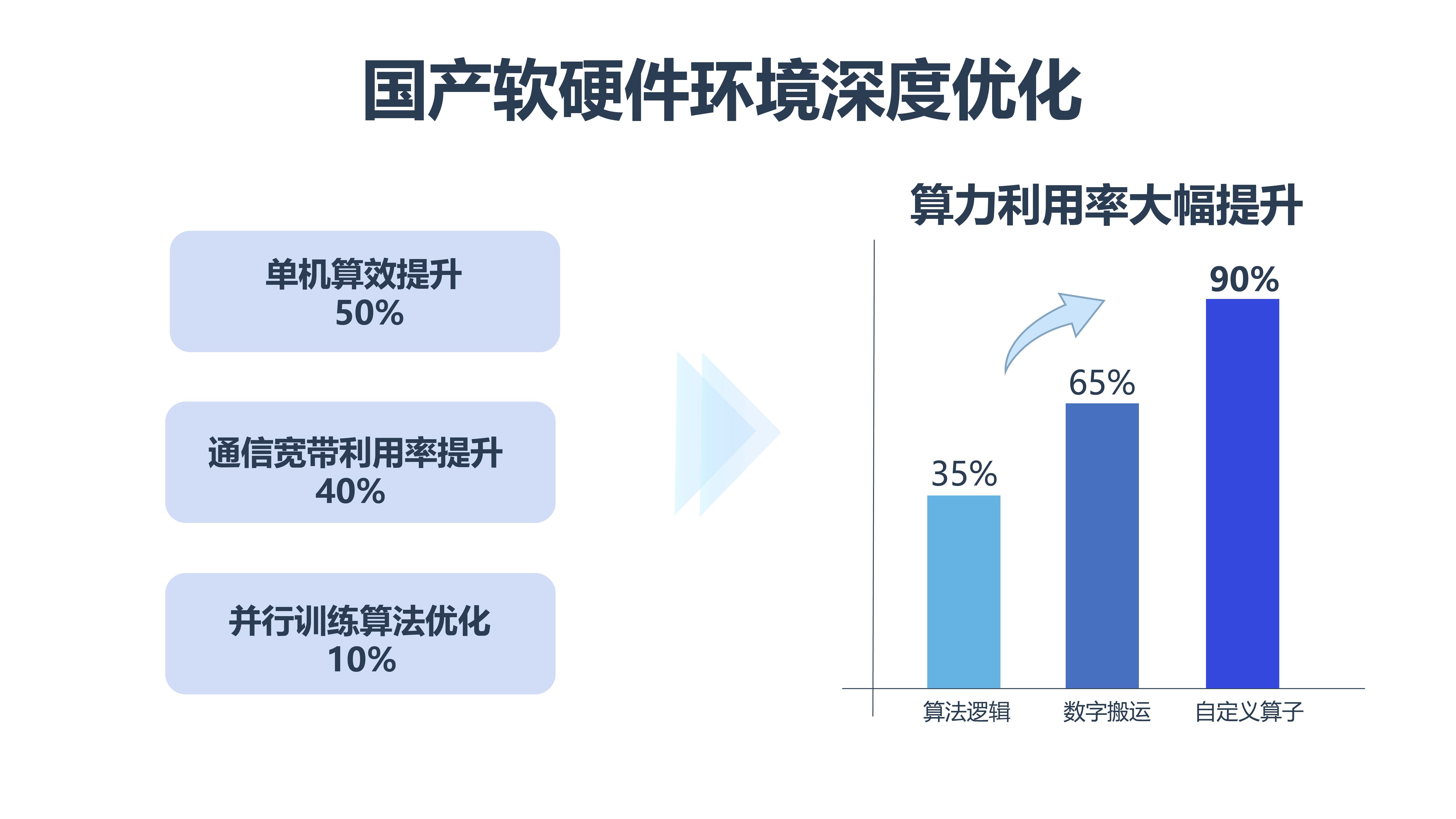
| TI模型、TI设备 (优化前)(8TOPS*4) | TI模型、TI设备 (优化前)(8TOPS*4) | TI模型、TI设备 (优化前)(8TOPS*4) | TI模型、TI设备 (优化前)(8TOPS*4) | TI模型、TI设备 (优化前)(8TOPS*4) | |
| 每帧计算量(GFLOP) | 6.36 | 6.36 | 6.36 | 6.36 | 6.36 |
| 每帧推理耗时(ms) | 6.3 | 6.36 | 6.36 | 6.36 | 6.36 |
| 利用率 | 3.15%*4 | 6.36 | 6.36 | 6.36 | 6.36 |
